
Why Data Matching is Critical to Data Warehousing Success
What is Data Warehousing?
tldr: A data warehouse is a database that copies data from an organization’s operational systems (like the sales system, the shipping system, the HR system, etc.) into one place and makes it available for management reporting. Now, take me to the curveball.
So, imagine you’re a database person and you work for a $2 billion company that has a CRM system to keep track of prospects and potential sales. Your company also has a separate ordering system where salespeople enter customer orders. In fact, because customers can place orders from your website, sometimes they enter data into the ordering system without the help of a salesperson.
One fine day the company’s president, realizing that you’re the only person who understands how to get data out of these systems (kinda funny, actually, given that you work for a $2B company), comes to you with the following question
What percentage of our prospects have bought things from us in the past?
After you think about it for a second, you realize that the only way to answer this question is to tie together data from the CRM system (i.e. prospective customers) and the sales system (existing customers and their purchase histories). So, you run queries against both databases and bring the data together into two new, temporary tables that you built just for this report. As we’ll see in a minute, you’re lucky, because the prospect ID in the CRM system becomes a customer number in the sales system; thus, there is a common key on which you can join these two tables together. You run your query and give the result to the CEO who, in turn, heaps praise, but not a raise, on you.
Then, the CEO hits you with a curveball (for those not in the US, it’s a baseball term meaning something unexpected), he asks,
Hey, can you do this same calculation every month AND show me the trend over time?
Now you’re facing the prospect of accessing both of your source systems every month, tying things together, and moving the results into a spreadsheet where you can graph it.
So, you say to yourself, “Curly” (I did mention that your name is Curly, didn’t I?), “how do I automate this to make it easier? And, having worked here at Massive Data Corps (I did mention that you work at MDC, didn’t I?) for all of two months now, I know that new, related questions are bound to come up. Really, how long will it be until someone asks not only the percentage of repeat customers but the value in Kuwaiti dinars of those repeat sales. (I did mention that MDC, a Michigan-based company that sells solely to customers only in the US transacts business in dinars, didn’t I? Why? Not sure, just stick with me here.).”
Well, it’s clear that you need some sort of tool to make this job easier. That tool, is a data warehouse (OK, there are a lot of other tools that you’ll probably need but, to get started, you need a DW).
What’s a data warehouse? Well, in the 1970’s and 1980’s, some tech folks foresaw this situation and hypothesized a solution. They said,
Hey, we hate copying data around but, since we have to in order to solve problems like this, why don’t we build a new database, a different kind of database. This one won’t capture any new data. All it will do is grab existing data, tie it together and make it available to people who need to do reporting and analysis?
This is exactly what they did. These databases went by a lot of different names, like reporting database, customer analysis database, decision support database, executive information database, and others. However, the name that stuck was data warehouse. This term was coined by Bill Inmon, who eventually became known as the father of data warehousing.
While his definition has shifted a little over time, his original still works pretty well (note that I added the text in parentheses):
A data warehouse is a subject oriented (i.e. it supports the analysis of subjects of interest, like customers or products), integrated (i.e. it ties together data from multiple places), time variant (i.e. it stores history), non-volatile (i.e. it might get new data but the old data in it doesn’t change) collection of data in support of management decisions.
Or, in less technical terms that you can use to support your funding request for building a data warehouse, it’s a database that
- Brings together data from a lot of different places but tries to make it look like it was always tied together
- Allows us to look at things from our managers’, not my computer geek’s, perspective
- Keeps that data but also stores changes to it over time so we can track how our company has changed, and
- Won’t change so, for example, if we sold a widget to you in Ohio last year and you moved to Michigan this year (good move, by the way), we’ll be able to track each sale to its proper location – this might not be the case in your sales system, BTW.
Having lived in the analytics world for over 30 years, I can tell you that there’s a lot of nuance to building a data warehouse. In later posts I’ll speak to things the data modeling, ETL architectures, and all sorts of things that sound very scary.
Anyhow, you get your funding, build your data warehouse, and become MDC’s employee of the month (IT Division, East Central Region). But, then the business gods throw you another curveball (it’s a good thing that you’re aware of what a curveball is, right?).
The Curveball
What do you do when MDC decides to buy TDC (Tiny Data Corp), whose stock just tanked due to a freak donut distribution accident? Well, you probably don’t do much… UNTIL your CEO says,
Curly, Dude (he is a Gen-Xer after all), now I need your future analyses to merge data from TDC’s customers in with data from our existing MDC customers. Also, Dude, I’m about to to buy some demongraphic data (yeah, I think he meant demographic) that I’d like to tie to each prospect and customer so we can learn a little more about them.
So, you start extracting the data from TDC’s CRM and sales systems and adding it to your new data warehouse. Being an experienced database expert, you see the problems right away: While you can tie together your MDC data with the prospect / customer ID numbers you have, TDC uses a completely different set of numbers. So, how will you know if the Irving Schmutznick on your customer list is the same as the Irving Schmutznick on theirs? Is this important? Hell yes! Here are just two reasons why (although I’m sure there are more)…
- Bad stats: If you have one sale to two customers (i.e. there are actually two different Schmutznicks and you’ve only sold to one of them), your ‘sales to existing people’ percentage is 50%. However, if these are actually both the same person (i.e. there’s only one Irving), you have an actual Schmutznick sales rate of 100% – you’ve sold to 100% of the Schmutznicks.
- Duplication costs: If the marketing department is using your data warehouse to list the people to whom they’re going to send catalogs, at a cost of $17.25 each, and there is really only one Irving Schmutznick, they’re going to send two catalogs when only one is needed.
So, it’s pretty important to find all of the replicas across your databases and treat them as single entities.
While all this is going on, you also reach out to DDC (Demon Data Corp – damn, it turns out he was right!) to purchase the demongraphic / demographic data. That data contains each person’s name, address, income level, and, for some reason, shoe size. What it doesn’t contain, is your customer number. Still, you need to tie this to all of your internal data.
Hitting the Curveball (it’s another baseball thing, just go with it)
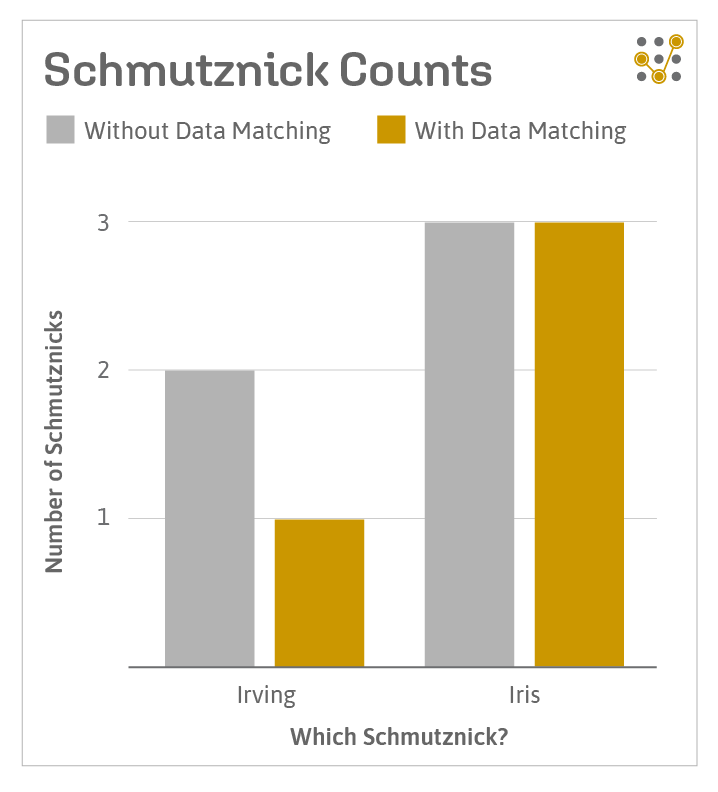 So, to solve this problem you need what we call a data matching solution. A data matching solution can analyze your data and indicate when the same entity is represented multiple times, i.e. it addresses what is known, in some circles, as the problem of Schmutznick duplication. I happen to know of just such a tool. It’s called Golden Record.
So, to solve this problem you need what we call a data matching solution. A data matching solution can analyze your data and indicate when the same entity is represented multiple times, i.e. it addresses what is known, in some circles, as the problem of Schmutznick duplication. I happen to know of just such a tool. It’s called Golden Record.
Golden Record looks at data sets, recognizes the Schmutznick duplications, and assigns its own master key to each Schmutznick in each data set. (for the record, it also works with Smiths, Joneses, Chopras, Andersens and any other name. It even works with product names, location names, and just about anything else that you might ever need to match). You can use Golden Record’s master key to instantly find that there is actually only one Irving Schmutznick and to find the key his records have in each of your systems as well as his demongraphic values. Interestingly enough, it can also tell you that there are actually three different Iris Schmutznicks and the keys for each of them.
So…
If you find yourself in a Schmutznick situation when you’re building a data warehouse or facing some other data integration challenge where you’ve got to tie together multiple, unintegrated data sets, let’s talk! Fill out the contact form below and we’ll get to you quite quickly.
Thanks!

About the Author
Describing himself as a recovering CPA, Ben Taub served as an accountant and auditor early in his career. He quickly shifted careers to his primary interest of information technology, data management, and decision support techniques. Before starting the analytics consulting and staffing company Dataspace, he was an early employee of business intelligence pioneer MicroStrategy. He now also oversees Golden Record, a cloud-based data matching and deduplication system which grew out of needs he saw in his various consulting assignments.
Ben has led efforts in the field of analytics, data management, and data warehousing for over 30 years and has coauthored three books on the topic, ORACLE8 DATA WAREHOUSING, ORACLE 8I DATA WAREHOUSING, and SQL SERVER 7 DATA WAREHOUSING, the first two in the Oracle Press series and the last published by the Osborne division of McGraw Hill. He has also spoken frequently and advises major corporations and charitable organizations on issues of analytics and data warehousing strategy.
Ben has a Bachelor’s degree in Economics and Business from Lehigh University and a Master of Business Administration from The University of Michigan. You can reach him at Benjamin.Taub@Dataspace.com.
Learn about data warehouses and get a laugh too!
Thanks, Adam!